EURECOM KINECT FACE DATASET
Eurecom
Description
Depth information has been proved to be very effective in Image Processing community and with the popularity of Kinect since its introduction, RGB-D has been explored extensively for various applications. Therefore, the need for the development of Kinect image & video database is crucial.
Here, our effort is to create a Kinect Face database of images of different facial expressions in different lighting and occlusion conditions to serve various research purposes.
Introduction

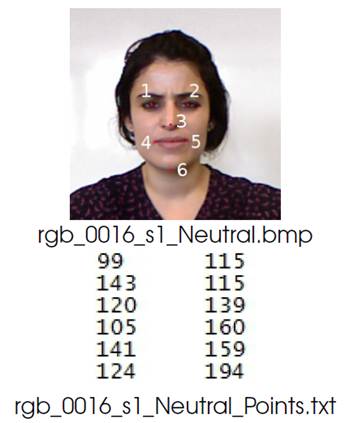
Acquiring process
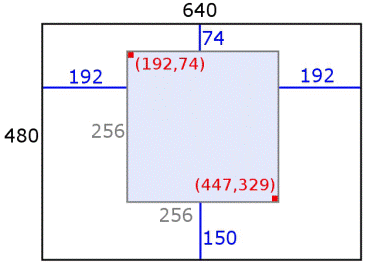
Structure
The structure of the database is illustrated in the following hierarchy [figure 4]
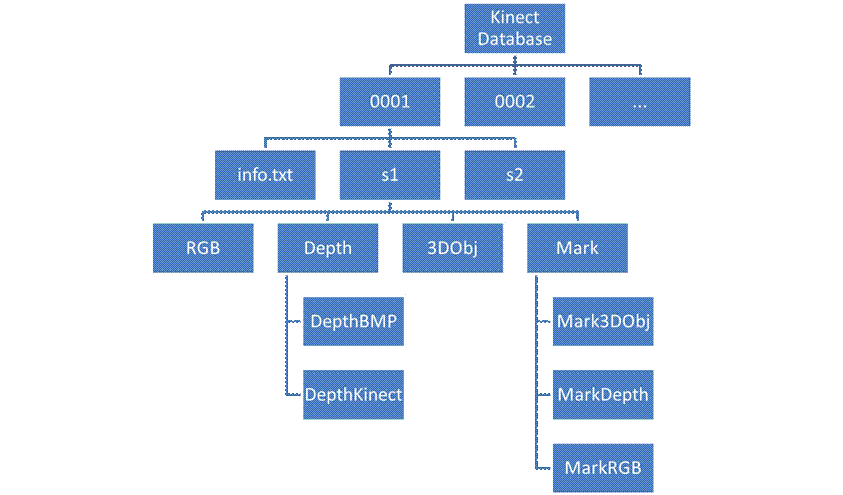
Where, the meaning of subpart is as follows:
0001: Folder name with person identifier 0001, each person is determined by an identifier of 4 digits.
Info.txt: some information about the person (ID, Gender, Year of born, Glasses (this person wears the glasses or not), Capture time of each session (format: yyyy:mm:ddhh:mm:ss))
S1: Session 1 (there are 2 session: S1 and S2)
RGB: Contains the RGB images, the file names are in the format: rgb_personIdentifier_session_faceStatus.bmp
Depth: Contains the Depth information
DepthBMP: Contains the .bmp depth image, the file names are in the format: depth_personIdentifier_session_faceStatus.bmp
DepthKinect: Contains the .txt files of the depth information from the sensor of each pixel in the original coordinates (before cropping at size 640x480), file names format:depth_personIdentifier_session_faceStatus.txt
3DObj: Contains the .obj 3D Object files, format of the file names: depth_personIdentifier_session_faceStatus.obj
Mark: Contains the information of the marked points
Mark3DObj: Contains the .txt files composed of the coordinates in 3D Object space, file names format: depth_personIdentifier_session_faceStatus_Points_OBJ.txt
MarkDepth: Contains the .txt files composed of the coordinates in the original Depth image coordinates (before cropping at size 640x480), file names format:depth_personIdentifier_session_faceStatus_Points_TXT.txt
MarkRGB: Contains the .txt files composed of the coordinates in 2D RGB image space, file names format: rgb_personIdentifier_session_faceStatus_Points.txt
From KINECT Video to Animatable Face Model
Obtaining the database
Reference
Any publication using this database must cite the following paper
Rui Min, Neslihan Kose, Jean-Luc Dugelay, “KinectFaceDB: A Kinect Database for Face Recognition,” Systems, Man, and Cybernetics: Systems, IEEE Transactions on , vol.44, no.11, pp.1534,1548, Nov. 2014, doi: 10.1109/TSMC.2014.2331215
@ARTICLE{IEEETransactions,
author={Rui Min and Neslihan Kose and Jean-Luc Dugelay},
journal={Systems, Man, and Cybernetics: Systems, IEEE Transactions on},
title={KinectFaceDB: A Kinect Database for Face Recognition},
year={2014},
month={Nov},
volume={44},
number={11},
pages={1534-1548},
doi={10.1109/TSMC.2014.2331215},
ISSN={2168-2216},}
Interested researchers can refer to the Florence Superface Dataset at http://www.micc.unifi.it/vim/datasets/4d-faces/, in order to test their algorithms on a separate dataset, and thus use diverse sets for training and test.
Contact
support
If you have any question or request regarding the EURECOM Kinect Face Dataset, please contact Prof. Jean-Luc DUGELAY via jld@eurecom.fr
- +33 (0)4 93 00 81 00
- 2229 route des crêtes, BP 193, Sophia-Antipolis Cedex, F-06560